
SQLiteをはじめとしたデータベースは、Excelなどのアプリとは違いプログラマー以外が直接操作をするのが難しいというデメリットがあります。
データベースは基本的にプログラムから操作する前提でできています。普段はアプリの裏でうごいていて、ユーザーがデータベースの存在を意識することはありませんが、何かしらの理由でユーザーに操作させるには、それ用のプログラムとUIを用意するのがセオリーかと思います。これってすごい面倒なんですよね。そんなときにExcelから一発でデータベースに変換できたら便利だね、というお話です。
最強の表作成ツール Excel
Excelは表計算アプリなわけですが、実際の用途はぶっちぎりトップが「一覧表として」でしょう。関数が1つも使われていないブックなんて、めずらしくも何ともないですよね。本来、こういった用途にはWordやPowerPointを使うのがいいのでしょうが、多少印刷がズレようがExcelを使ってしまうのは、その驚異的な表作成のしやすさにあります。
こうして今日もExcelの一覧表は量産されていきます。
ExcelをDBのUIに
Pythonで永続的にデータを扱いたい場合、データベースを使います。標準モジュールにSQLiteのドライバーがあるので、特別な準備も必要なく使えます。が、前述のように非プログラマーには扱いが難しいです。大勢が利用するWEBアプリならいざしらず、業務用のちょっとしたスクリプトにいちいちUIをこしらえるのは割に合いません。
データベースごとにビューワーやエディタツールもあるにはありますが、わかってるヤツ以外使うなオーラが半端ないです。そこでみんなのアイドルExcelちゃんの出番です。
Excelであれば、オフィスワーカーなら目をつぶってでも(?)表がつくれます。表というのはすなわちデータベースのテーブルなわけで、Excel→SQLiteができればExcelをUIとして使えます。
調べてみたところExcelからCSVへ書き出して、SQLiteへ取り込む方法がありました。でも、それって面倒くさいですよね?関数が1つもない表を作る方々にCSVでの出力操作を頼めません。文字コードの指定なんてしてくれる気がしませんよね。マクロを仕込んでおいてCSV出力させればいいのかもしれませんが、もっと簡単、スマートにやりたくないですか?
はい、忘れてはいけません。我らには神から賜りし至高のモジュールOpenPyXLがあるではありませんか!
ExcelシートをSQLiteテーブルに変換
前提としてExcelからのデータ投入は、初期データや設定値などの更新が低頻度なものを想定しています。頻繁に更新が必要なデータはプログラムからだけ書き換えるか、専用UIを用意すべきです。
次のようなExcelファイルがあります。
1枚目のシートはさいたま市の区名と区役所のURL。
2枚目はさいたま市の町別人口。
いずれもさいたま市のWEBサイトで入手したデータです。
シート構成はこうです。
このファイルをSQLiteのテーブルへ変換します。データベースはすでに作成されているとします。テーブルはまだありません。
まずは、ExcelシートのデータをSQLiteのテーブルにどのように当てはめるのかをdict(以下db_map)で定義します。
excel_db_map = {
'WEBサイト': {
'min_row': 2,
'table_name': 'web',
'column': {
'url': {'type': 'text', 'index': 1},
'div_name': {'type': 'text', 'index': 2}
}
},
'人口': {
'min_row': 2,
'table_name': 'population',
'column': {
'div_code': {'type': 'text', 'index': 1},
'div_name': {'type': 'text', 'index': 2},
'town_name': {'type': 'text', 'index': 3},
'town_kana': {'type': 'text', 'index': 4},
'households': {'type': 'int', 'index': 5},
'man': {'type': 'int', 'index': 6},
'woman': {'type': 'int', 'index': 7},
}
}
}あれ、この次点でCSVにするより面倒じゃない? db_mapにはシート名をキーにして次のような構造のdictを要素に持たせています。
{
'min_row': Excelシートの変換開始行番号(列名含まず),
'table_name': SQLiteのテーブル名,
'column': {
SQLiteのカラム名1: {'type': データ型, 'index': Excelシートの列番号},
SQLiteのカラム名2: {'type': データ型, 'index': Excelシートの列番号}
}
}頑張ればシートを解析して自動でこれと同様のことをできそうですが、わざわざこんなにしている最大の理由は、システム周りに日本語を使いたくないためです。
SQLiteは日本語のカラム名もいけるようですが、私のシステムに日本語恐怖症がそうさせません。そもそも仕様でダメなDBもあったと思います。プログラムをやるならコレとShift-JIS恐怖症にはかかっておいた方が良いです。
Excelシート側にこれらのパラメーターを持たせてそれを取り込むという方法や、そもそもExcelで日本語列名を禁止する方法も考えられますが、既存のExcelファイルをそのまま取り込めるというメリットがなくなってしまうのでやめます。
db_mapが定義できれば、もう終わったようなもので、あとはこれを元にExcel→SQLite変換ロジックをつくります。大まかな流れは「db_mapに定義されたSQLiteのテーブルのカラムにExcelの指定された列番号のセル値を入れていく。これを最終行まで繰り返す。これを指定されたシートの分繰り返す」となります。
こうなりました。
import os
import openpyxl as excel
import sqlite3
def db_insert(book, db_map):
current_dir = os.path.dirname(__file__)
dbname = os.path.join(current_dir, 'saitama.db')
conn = sqlite3.connect(dbname)
conn.row_factory = sqlite3.Row
cur = conn.cursor()
for sheet_name in db_map:
db_init(db_map, cur, sheet_name)
sheet = book[sheet_name]
col_name = []
val = []
min_row = db_map[sheet_name]['min_row']
table_name = db_map[sheet_name]['table_name']
for k, v in db_map[sheet_name]['column'].items():
col_name.append(k)
val.append(v['index'])
col_names = ','.join(col_name)
for r in sheet.iter_rows(min_row=min_row):
values = []
if r[0].value is None:
break
for v in val:
cell_val = r[v-1].value
if type(cell_val) is not str and type(cell_val) is not int and cell_val is not None:
values.append(str(cell_val))
else:
values.append(cell_val)
place_holder = ','.join('?'*len(values))
sql = f'INSERT INTO {table_name} ({col_names}) VALUES({place_holder})'
cur.execute(sql, tuple(values))
conn.commit()
cur.close()
conn.close()
def db_init(db_map, db, sheet_name):
param = []
table_name = db_map[sheet_name]['table_name']
for k, v in db_map[sheet_name]['column'].items():
param.append(f"{k} {v['type']}")
params = ','.join(param)
db.execute(f'CREATE TABLE IF NOT EXISTS {table_name}({params})')
db.execute(f'DELETE FROM {table_name}')
wb = excel.load_workbook('C:\\Users\\ore\\Desktop\\saitama_city.xlsx', data_only=True)
insert_data(wb, excel_db_map)db_insertがメインの関数です。db_initはデータベースの初期化を行います。少し詳しく見ていきます。
解説
初期化処理db_init関数はdb_mapとデータベース接続と対象のシート名を引数に取り、テーブルの(なければ)作成と全DELETEを実行します。SQLは簡単なものなので説明は端折ります。肝はこの部分で
param = []
for k, v in db_map[sheet_name]['column'].items():
param.append(f"{k} {v['type']}")
params = ','.join(param)これで、SQLの CREATE TABLE に与えるパラメーターを組み立てています。
dictオブジェクトのitemsメソッドは要素を[key,value]の形で返してきます。イテレーターを持っているのでforで回すことで全要素をこの形で取り出していくことができます。これを使ってdb_mapの[sheet_name][‘column’]の要素を変数k,vへ代入しています。たとえば
'WEBサイト': {
'min_row': 2,
'table_name': 'web',
'column': {
'url': {'type': 'text', 'index': 1},
'div_name': {'type': 'text', 'index': 2}
}
}このdictをfor~itemsが次の2つのlistとして返します。※sheet_nameは引数で’WEBサイト’と与えられているものとします。
['url',{'type': 'text', 'index': 1}]
['div_name', {'type': 'text', 'index': 2]簡単のため、このうち上段のlistのみに注目します。アンパック代入により変数k,vは次のようになります。
k = 'url'
v = {'type': 'text', 'index': 1}CREATE TABLEで必要な情報は、テーブル名、カラム名とデータ型です。テーブル名はdb_mapのtable_nameキーから取得しています。カラム名は変数kに入りました。vの中身はまたdictでデータ型の情報は、そのうちtypeというキーで定義されている値です。
これらを文字列として結合します。生成した文字列はparam変数(list)へ格納しておきます。
param.append(f"{k} {v['type']}")これを全要素に繰り返します。最後にparamの全要素をカンマ区切りで1つの文字列とします。
params = ','.join(param)例で使ったdictから最終的に次のような文字列ができます。
table_name = 'web'
params = 'url text,div_name text'これらを CREATE TABLE へ展開することで、db_mapの定義にもとづいたテーブルが作成されます。
db.execute(f'CREATE TABLE IF NOT EXISTS {table_name}({params})')メイン関数ではまずデータベースの接続をしていますが、これは定型句みたいなものなので飛ばして、SQLのパラメーターの作成は初期化関数と同じ手法でおこないます。ただしこちらではアンパックした変数vのうちindexキーの方を使います。indexキーの値はExcelシートの列番号をあらわす数値です。
それぞれを別のlistへ格納しておきます。col_nameにはカラム名、valにはExcelの列番号が入ります。listなので順番は保証されます。
col_name = []
val = []
for k, v in db_map[sheet_name]['column'].items():
col_name.append(k)
val.append(v['index'])valにはExcelシートの列番号が格納されていますので、OpenPyXLのiter_rowsメソッドでシートを上から行方向へ走査していって、この列番号のセル値を1行ごとに取得していきます。min_rowは走査を開始する行番号です。Excel表のタイトル行などを除外することができます。
iter_rowsメソッドはセルの値に関係なく使用されているセル範囲を返してきます。最初の数行だけデータがあり、あとは空白だけど罫線は100行目まで引いてあるといった場合、100回ループすることになります。これは無駄なので第1列のセル値が空白の場合は処理を止めるようにします。
r[v-1].valueと列番号を1減らしているのは、iter_rowsメソッドのリターン(1行分のセルオブジェクトのタプル)のインデックスは0始まり、Excelのセルのインデックスは慣例として1始まりなのでこの差をここで吸収しています。
SQLiteではデータ型はあまり重要視されていないのですが、OpenPyXLでセル値を取得すると、たとえば「10:00」とセルに入力されているとdatetime.time型として取得されます。
これをそのままINSERTのパラメーターにはめ込むと怒られます。SQLiteさんに「そんな型はねーんだよ」と言われます。そこでstrとint以外の型は全部文字列表現を取得するようにしています。ただしOpenPyXLでは空セルはNoneで返ってくるので、それは文字列表現にしないでそのまま突っ込みます。SQLiteにはnullで入ります。
以上の処理が次の部分です。
for r in sheet.iter_rows(min_row=min_row):
values = []
if r[0].value is None:
break
for v in val:
cell_val = r[v-1].value
if type(cell_val) is not str and type(cell_val) is not int and cell_val is not None:
values.append(str(cell_val))
else:
values.append(cell_val)最後にSQL文字列へ展開してINSERT文を作成するわけですが、カラム名については初期化関数と同じくカンマ区切りでいいのですが、VALUESについてはプレースホルダー「?」を使うと値をタプルで渡すだけで勝手に展開して当てはめてくれるので便利です。
そこで値(values変数)についてはカンマ区切りで要素の数だけ「?」をつなげます。そしてexecuteメソッドの第二引数へ値のタプルを渡します。すでにlistにしてあるので、tupleで変換します。
place_holder = ','.join('?'*len(values))
sql = f'INSERT INTO {table_name} ({col_names}) VALUES({place_holder})'
cur.execute(sql, tuple(values))まとめ
これで通常はPythonスクリプトでデータベースを利用して、初期データの投入や設定の変更などが必要な場合は「このExcelを書き換えて、このスクリプトをポチってね」で誰でもテーブルが更新できます。別の構造のExcelを取り込みたければmapだけ書き変えればOKです。
実行してデータベースビューワーで確認するとうまくいっているようです。
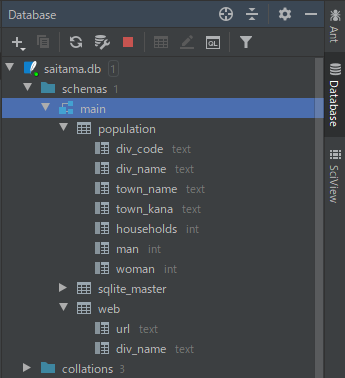
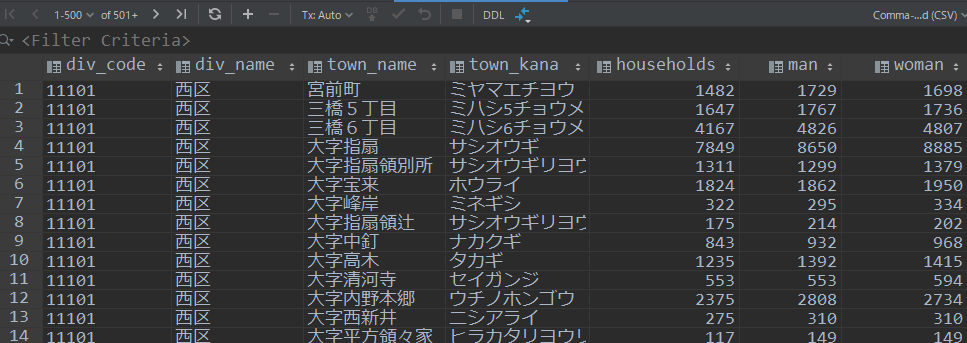
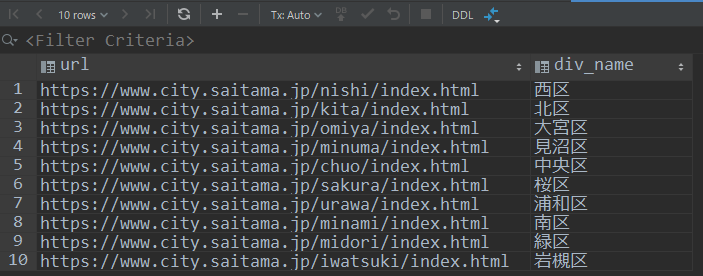
区名が両方のテーブルにあったりして、まだデータベースとしては改善の余地がありますが、それはまた別の話で、目的は達成できましたね。
Excelの元データは男女合計人口の列もあったので、無駄なので取り込み対象から外しました。と、こういったことがExcel側をさわらずに、db_mapでいくらでも制御できるのがCSV取り込みより優れた点、ということにしておきましょう。
ドライバーを別のDB用に差し替えれば、SQLite以外でも使えると思います。手持ちのPostgreSQLで、単純にドライバーだけ差し替えてみたんですがexecuteメソッドの仕様が違うので、多少ロジックの組み替えが必要でしたがいけました。
今回使用したスクリプトとExcelブックを次からダウンロードできます。
ファイルを入手する
おわり。

