
我々VBAerにとっては周知の事実ですが、Excel-VBAで時間がかかる処理と言えば、「ワークシートへのアクセス」と「ファイルを開く」です。前者については昔に比べてだいぶ速くなっている(ような気がする)のですが、後者は未だにワースト候補です。
百聞は一見にしかずで、実際にやってみます。
VBAでExcelファイルを開く速度
D:\saitama\に100個のExcelブックファイルがあります。1つのファイルサイズは数KBです。次のコードでExcelブックを読み込んで1つのセルの値を取得したら閉じる、を100個のファイルに対して実行します。時間計測コードでProcess Timeとして処理時間を、Buffer Lengthで取得データ個数をそれぞれ出力し検証します。
Sub excelReader()
Const TGT_DIR_PATH As String = "D:\saitama\"
Dim st
st = Timer
Dim fp As String
fp = Dir(TGT_DIR_PATH & "*.xlsx")
Application.ScreenUpdating = False
Application.EnableEvents = False
Application.Calculation = xlCalculationManual
Dim wb As Workbook
Dim buf As Collection
Set buf = New Collection
Do While Len(fp) > 0
Set wb = Workbooks.Open(TGT_DIR_PATH & fp, ReadOnly:=True)
buf.Add wb.Worksheets(1).Range("a1").Value
fp = Dir()
wb.Close
Loop
Application.ScreenUpdating = True
Application.EnableEvents = True
Application.Calculation = xlCalculationAutomatic
Debug.Print "Process Time:" & Timer - st
Debug.Print "Buffer Length:" & buf.Count
End Sub結果は
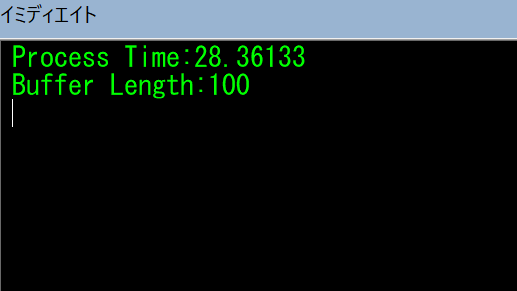
28秒でした。
遅すぎですね。
なお、私のPCは超高性能なので、そんじょそこらの事務用PCでこれ以上の速度が出ることはあり得ないといっていいでしょう。
PythonでExcelファイルを開く速度
Pythonで同じことをやってみます。ExcelファイルはOpenPyXLで扱います。コードは次のようにしました。
import os
import time
import openpyxl as excel
st = time.time()
TGT_DIR_PATH = r'd:\saitama'
buf = []
for fn in os.listdir(TGT_DIR_PATH):
wb = excel.open(os.path.join(TGT_DIR_PATH, fn))
ws = wb.active
buf.append(ws['a1'].value)
process_time = time.time() - st
print('Process Time:' + str(process_time))
print('Buffer Length:' + str(len(buf)))結果は
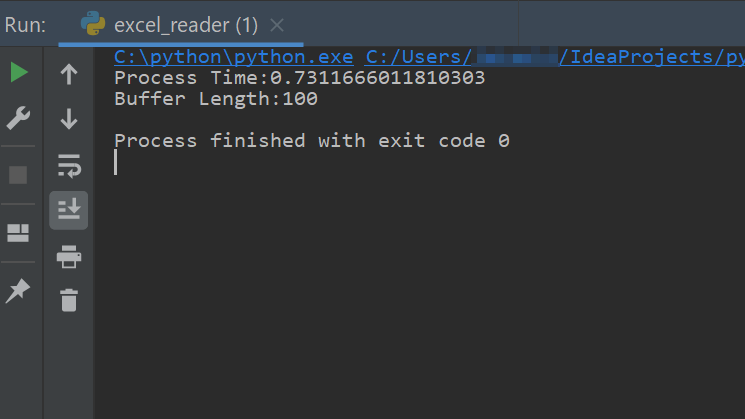
0.7秒でした。
圧倒的に速いです。
これほどまでに差がつく原因としては
・VBAはExcelブックのすべてを読み込んでいる
・OpenPyXLはExcelブックのxmlだけを読み込んでいる
ためだと推測します。
まぁ、そうなるよなと。
じゃあそのままPythonで全部やってしまえ、といきたいところなのですが、今回の主たる目的はPythonでデータ取得してVBAでExcelへ取り込むことです。
というのも、次のようなシチュエーションで使いたいからです。そのためOpenPyXLのある弱点が関係してきます。
Excelをファイルマネージャーにする
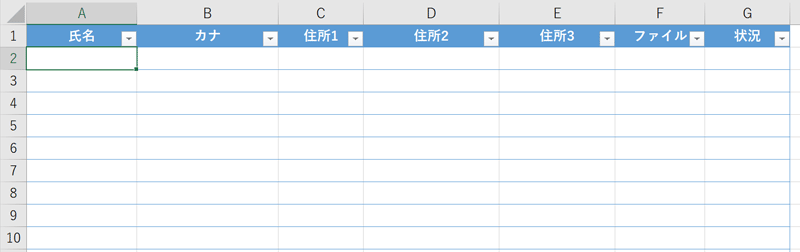
このようなシートに1名分の個人情報が記録されているブックがあります。

このブックにさまざまな情報を別シートで付与して1ファイルで1顧客を管理することにします。256名の顧客がいれば、256個のファイルができます。
このやり方が良いか悪いかはさておき、顧客情報に限らずとも、申請書、報告書などなど、Excel原理主義が浸透している現代社会においては割と遭遇する状況ですよね。
ここから必要な顧客のファイルを探し出すときに、1つずつファイルを開いていては話にならないので、ファイル名に識別記号を付けるなどの工夫をすると思いますが、もっとスマートに管理用のExcelブックを作成し、そこへ必要な情報を網羅しておくという方法があります。
Excelシートをファイルマネージャーのように使ってやろうということです。
ざっと次のようなイメージになります(データは架空個人情報作成サイトで生成したものです)。
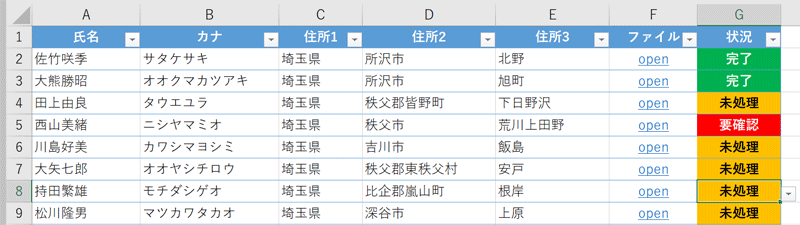
ファイルの基本的な情報を一覧で網羅し、ハイパーリンクからそのファイルを開き編集ができるようにします。また進捗をドロップダウンで切り替えて管理できるようにしています。
ここへの登録処理を順当にVBAだけでやると、次のようなコードで(重要じゃない部分は省略)
Enum col
Name = 1
kana
addr1
addr2
addr3
filePath
Status
End Enum
Sub excelReader()
Const TGT_DIR_PATH As String = "D:\saitama\"
Dim fp As String
fp = Dir(TGT_DIR_PATH & "*.xlsx")
Dim srcWb As Workbook
Dim r As Long
r = 2
Do While Len(fp) > 0
Dim ws As Worksheet
Set ws = ThisWorkbook.Worksheets(1)
Set srcWb = Workbooks.Open(TGT_DIR_PATH & fp, ReadOnly:=True)
With srcWb.Worksheets(1)
ws.Cells(r, col.Name).Value = .Range("a2").Value
ws.Cells(r, col.kana).Value = .Range("b2").Value
ws.Cells(r, col.addr1).Value = .Range("c2").Value
ws.Cells(r, col.addr2).Value = .Range("d2").Value
ws.Cells(r, col.addr3).Value = .Range("e2").Value
ws.Hyperlinks.Add ws.Cells(r, col.filePath), _
TGT_DIR_PATH & fp, TextToDisplay:="open"
ws.Cells(r, col.Status).Value = "未処理"
End With
r = r + 1
fp = Dir()
srcWb.Close
Loop
End Sub100個のファイルを反映させる時間を計測してみると
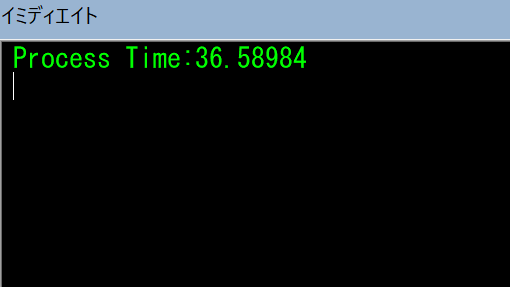
36秒かかりました。ワークシートアクセスが多いコードとはいっても遅すぎ。
実際にはまるまる100個読むことは最初だけで、あとは更新されたものだけ読むようにするなどしますが、それなりの「待ち」が発生することは避けられません。
このファイルに直でOpenPyXLからデータを流し込むこともできますが、OpenPyXLは書式の再現性がかなりおおざっぱです。おそらく保存時にどこかの書式情報が失われます。なので、私は書式設定がされたExcelブックはOpenPyXLでの保存は禁忌としています。
よって作戦としては
- OpenPyXLでファイルを読み込み、それを何らかに出力
- VBAで1のデータを読み込みシートに反映
することで、高速化します。
VBA-Pythonデータ連携作戦
で、その「何らか」ですが、一番簡単なテキストデータで仲介したいと思います。私のKindleライブラリにある本もこう言っています。
組み立て部品の原則:テキストストリームを読み書きする、コマンドラインで使用できるソフトウェアを設計しましょう。シリアライズされたプロトコルめいたインタフェースより、テキストストリームの様な単純なインタフェースを選択してください。その方が、複数のソフトウェアを、異なる仕事のために、組み合わせて利用できます。
上田勲. プリンシプル オブ プログラミング 3年目までに身につけたい 一生役立つ101の原理原則 (Kindle の位置No.2521-2528). 株式会社秀和システム. Kindle 版.
(中略)
多少の走査のオーバーヘッドがあったとしても、汎用的なテキストフォーマットのデータストリームを、自由に読み書きできる便利さを享受するべきです。
まさに今回の事例のことをずばり言っているかのようですね。そうします。
具体的にはOpenPyXLで取得したセル値をCSVで保存して、そいつをVBAから読みにいきます。
Excelブックを順次CSVにしていくコードは
import csv
import os
import time
import openpyxl as excel
from openpyxl.utils.exceptions import InvalidFileException
st = time.time()
TGT_DIR_PATH = r'd:\saitama'
with open(os.path.join(TGT_DIR_PATH, 'buf.csv'),
mode='w',
encoding='shift-jis',
newline='') as buf:
cw = csv.writer(buf)
for fn in os.listdir(TGT_DIR_PATH):
try:
wb = excel.open(os.path.join(TGT_DIR_PATH, fn))
ws = wb.active
name = ws['a2'].value
kana = ws['b2'].value
address1 = ws['c2'].value
address2 = ws['d2'].value
address3 = ws['e2'].value
cw.writerow([name, kana, address1, address2, address3])
except InvalidFileException:
continue
process_time = time.time() - st
print('Process Time:' + str(process_time))つまづきポイントはopenの引数に newline=” を渡さないと1行おきに空白行が入ってしまうのと、except InvalidFileException でエラーをキャッチしないとOpenPyXLがExcelファイル以外を開こうとして落ちます。
またShift-jis駆逐委員会構成員としては誠に不本意ながら encoding=’shift-jis’ にしないとVBA側での取り込みがクソ面倒になるのでそうしています。
処理時間は
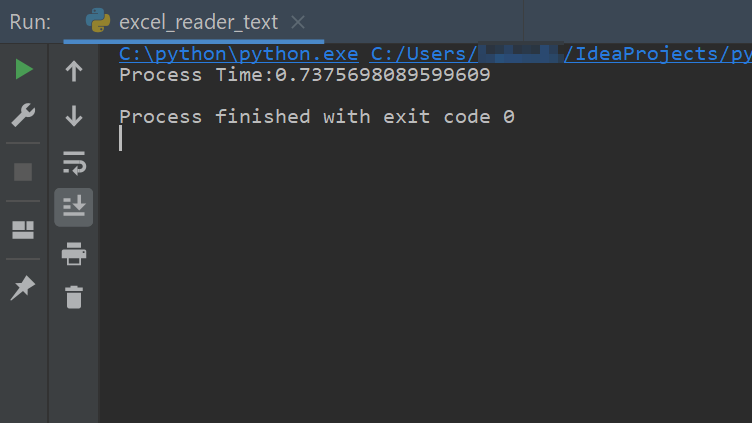
まったく変わりません。いいですね。buf.csvが生成されました。
このPythonスクリプト(excel_reader_text.py)をVBAから実行したいので、WScript.Shellを使ってコマンドラインで実行するとします。スクリプトファイルはデータと同じ場所へ配置し、環境変数は設定済みとします。
次のプロシージャを管理用ブックに追加します。
Sub executePy()
Dim wss As Object
Set wss = CreateObject("WScript.Shell")
Dim cmd As String
cmd = "python D:\saitama\excel_reader_text.py"
wss.Run cmd, 0, True
End Subコードの意味はインターネッツに山ほど解説があるので省略します。私もコピペしてきただけです。パスを手抜きでハードコーディングしていますが、Publicな定数とか引数で持ってくるべきですね。
続けてCSVを読み込みシートに展開するプロシージャを作成します。コードは同じくインターネッツから拾ってきたのを改造し
Sub importCSV()
Dim buf As String
Dim cl
Dim r As Long
r = 2
Open "D:\saitama\buf.csv" For Input As #1
With ThisWorkbook.Worksheets(1)
Do Until EOF(1)
Line Input #1, buf
cl = Split(buf, ",")
.Cells(r, col.Name).Value = cl(0)
.Cells(r, col.kana).Value = cl(1)
.Cells(r, col.addr1).Value = cl(2)
.Cells(r, col.addr2).Value = cl(3)
.Cells(r, col.addr3).Value = cl(4)
.Hyperlinks.Add .Cells(r, col.filePath), cl(5), TextToDisplay:="open"
.Cells(r, col.Status).Value = "未処理"
r = r + 1
Loop
End With
Close #1
End SubこんなのVBA側で標準クラスとして用意しといてくれやって思いますが、全部自分でやんなきゃいけないあたりにVBAの時代遅れ感、Microsoftからのいらない子認定度合いが如実にあらわれますね。UTF-8はこれではダメでさらにゴチャゴチャやらされます。いちVBAerとして哀愁を感じざるを得ません。
なお、コードを読んでもらえばわかりますが、データの途中にデリミタではない「,」があると終わりですので、本来はCSV作成の方で対処するべきですが面倒くさくてやっておりません。
部品はそろったので、それぞれを管理用ブックに作ったメインプロシージャからコールします。時間も計ります。
シートはクリアしてCSVファイルは削除しておきます。
コードは
Sub main()
Dim st
st = Timer
Application.ScreenUpdating = False
Application.EnableEvents = False
Application.Calculation = xlCalculationManual
Call executePy
Call importCSV
Application.ScreenUpdating = True
Application.EnableEvents = True
Application.Calculation = xlCalculationAutomatic
Debug.Print "Process Time:" & Timer - st
End Sub実行すると結果はこうなり
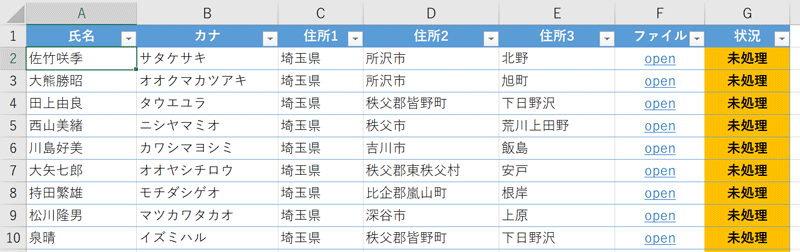
そして時間は
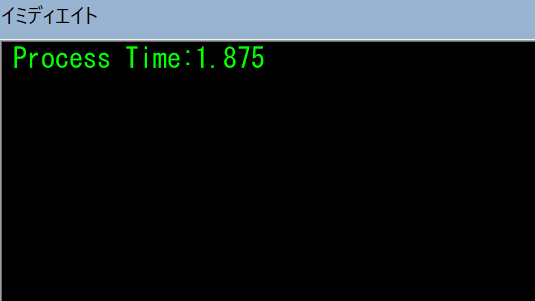
約1.9秒でした。
まぁいいんじゃないでしょうか。それくらいだったら待とうじゃないですか。
あとは付帯処理、たとえばすでに登録済みのファイルが更新されたら一覧に追加するのではなく書き換えをする、フォルダ内のファイルの最終更新日時をどこかに確保しといてそれ以降に更新されたファイルだけ開いて確認する、などを作っていけば実用できそうです。
まとめ&おまけ
PythonにはSQLiteドライバーが標準装備なので、何もしなくても簡単に使えます。
だったら、ということでSQLiteで仲介したらどうなるかやってみます。※ただしExcel側の受け入れ準備はそれなりに面倒です。
出力先をCSVファイルではなくデータベースにします。customerというテーブルをあらかじめ作成してあります。
import sqlite3
(省略)
conn = sqlite3.connect(r'D:\saitama\buf.sqlite')
cur = conn.cursor()
for fn in os.listdir(TGT_DIR_PATH):
try:
wb = excel.open(os.path.join(TGT_DIR_PATH, fn)
(省略)
file_path = os.path.join(TGT_DIR_PATH, fn)
cur.execute('INSERT INTO customer VALUES(?,?,?,?,?,?)',
(name, kana, address1, address2, address3, file_path))
except InvalidFileException:
continue
conn.commit()
cur.close()
conn.close()実行時間は
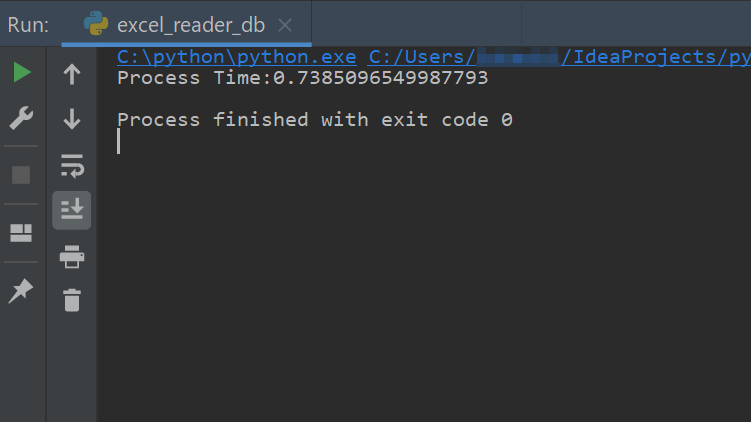
データベースはスピード命のソフトウェアなのでテキストより大幅に遅くなることはないとは思っていましたが、テキストでもすでに超スピードだったので大差ないですね。
件数が莫大になってくるとデータベースの優位性が発揮されるかもしれませんが、今回のような用途ではその機会もなさそうです。
Excel側ではODBCで接続します。やり方はGoogle先生に聞いてください。ファイルを開くと同時に自動更新に設定しておくと勝手にシートが更新されます。
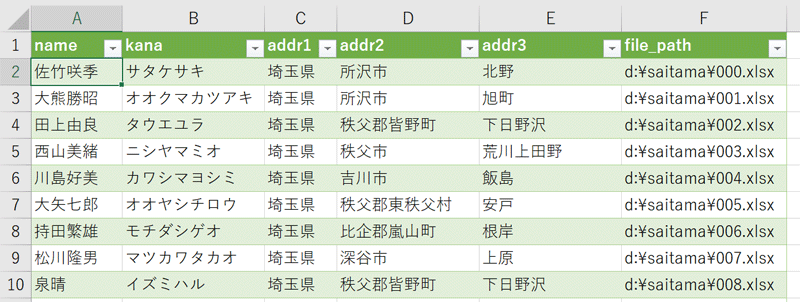
データベースから取り出した生データなので、ここからいろいろ見た目を加工する必要がありますが、使えなくはなさそうですね。
読み込みの正確な時間は計っていませんが、マウスカーソルがグルグルなって何かやってるな~はわかり、体感としてはCSVと大差なかったです。
そもそも、データベースにできるならExcelをビューワーにするメリットはあまりないです。Accessでリンクテーブルにしてしまった方が断然楽です。そしてそれをやるならサーバー型データベースにすべきで、サーバー型データベースを導入できる環境ならWebアプリでいいじゃんとなっていきそうですが、今回はここまでにしておきます。
ちなみに、CSVもVBAでシートへ展開する以外にExcelの外部データ取り込み機能で↑の画像と同じように生データを取り込めます。自動更新にしておくとCSVが更新されるとシートのデータも変わります。
今回の用途には適しませんが、CSVデータを見たいだけなら外部データ取り込みが簡単です。
追記:xlrdでやってみる
xlrdはVer2.0.0から.xlsx形式をサポートしなくなりオワコンとなられました。合掌。最新のxlrdではこれらのコードはxlsファイルに対してしか実行できません。
OpenPyXL信者の私ですが、風の噂でxlrdという同じようなことができるモジュールがあることを知りました。読み取り特化と聞いて速そうな感じがするのでやってみます。
コードを少し改造して
import csv
import os
import time
import xlrd
from xlrd.biffh import XLRDError
st = time.time()
TGT_DIR_PATH = r'd:\saitama'
with open(os.path.join(TGT_DIR_PATH, 'buf.csv'),
mode='w',
encoding='shift-jis',
newline='') as buf:
cw = csv.writer(buf)
for fn in os.listdir(TGT_DIR_PATH):
try:
wb = xlrd.open_workbook(os.path.join(TGT_DIR_PATH, fn))
ws = wb.sheet_by_index(0)
name = ws.cell(1, 0).value
kana = ws.cell(1, 1).value
address1 = ws.cell(1, 2).value
address2 = ws.cell(1, 3).value
address3 = ws.cell(1, 4).value
file_path = os.path.join(TGT_DIR_PATH, fn)
cw.writerow([name, kana, address1, address2, address3, file_path])
except XLRDError:
continue
process_time = time.time() - st
print('Process Time:' + str(process_time))実行時間は
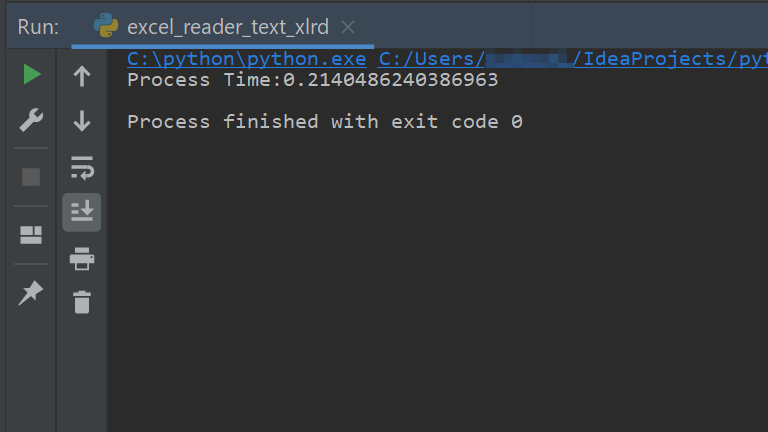
ちょっ、速すぎワロタw。
まさかの0.2秒でした。ホントに100回開いてんのかとCSVを見てみたらちゃんとできてます。今回の用途ではこの方法がベストですかね。
OpenPyXLと比べてセル指定が直感的にできないなどイマイチポイントはありますが、旧xls形式のブックが読めたりとグッドポイントもあるので今後用途によってはxlrdも使っていきたいと思います。
で、ここまできたら最後までいきたいので、xlrdで読み込んでPostgreSQLへぶち込んでAccessでリンクテーブルとして表示してみます。
出力先をPostgreSQLへ変更して
import psycopg2 as pg
from psycopg2 import extras
(省略)
TGT_DIR_PATH = r'd:\saitama'
HOST = 'localhost'
PORT = '5432'
DB_NAME = 'saitama'
USER = 'ore'
PASSWORD = 'oreore'
st = time.time()
rows = []
with pg.connect(
f'host={HOST} port={PORT} dbname={DB_NAME} user={USER} password={PASSWORD}') as conn:
with conn.cursor() as cur:
for fn in os.listdir(TGT_DIR_PATH):
try:
wb = xlrd.open_workbook(os.path.join(TGT_DIR_PATH, fn))
(省略)
file_path = os.path.join(TGT_DIR_PATH, fn)
rows.append((name, kana, address1, address2, address3, file_path))
except XLRDError:
continue
extras.execute_values(cur, 'INSERT INTO customer VALUES %s', rows)
process_time = time.time() - st
print('Process Time:' + str(process_time))実行速度は
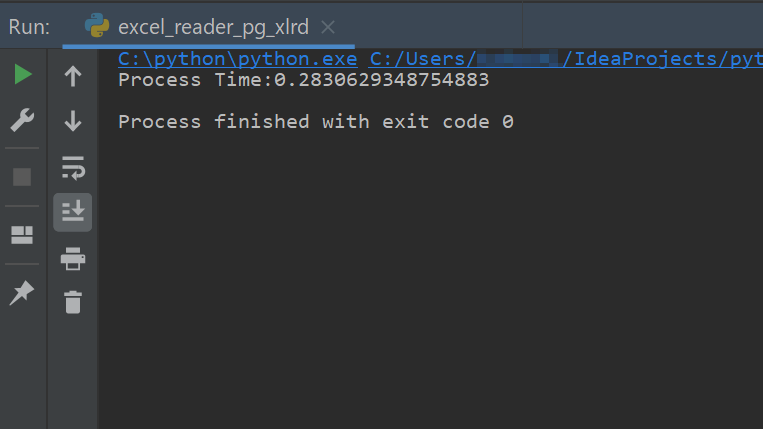
0.3秒を切り、速いです。さすがにSQLiteの時よりDBMSの図体がデカくなったのでテキスト出力との差がでますね(といってもmsecの世界ですが)。
この方式のメリットはこの時点でもうデータ処理が終わりなところです。ここからVBAで展開する必要がありません。実質100ファイルで0.3秒しか待たないということです。文句なし。
Access側ではODBCでリンクテーブルとして設定して、フォームで小綺麗に整えます。
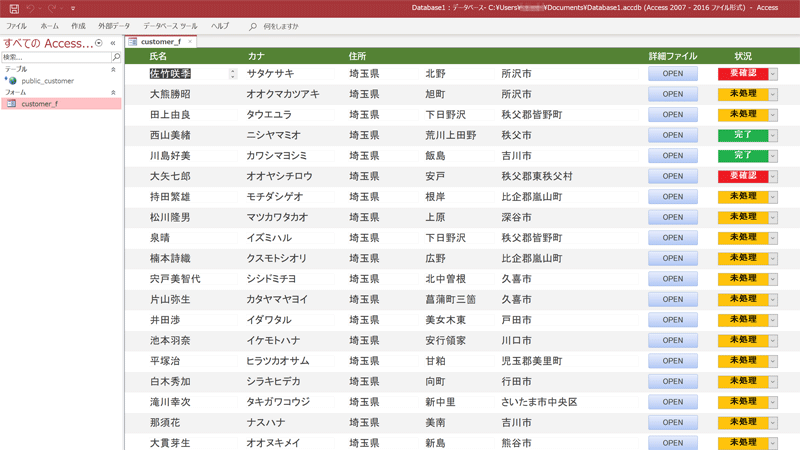
あとの登録済みファイルの更新処理やら、最終更新日時で開くファイルの判断やらはPython-PostgreSQL間だけでやっつければよく、そのときのデータ検索はDBMSのお家芸で、ExcelとVBAでやるより抜群に速いはずなのであえて検証はしません。
現実問題として最後の環境が整う事務所はほんの一握りで、実際はPythonすら使えないこともままあると思われ、xlrd+CSV+VBAでできればしめたものでしょうか。
何回も言わせていただきますが、事務用PCにはもれなくPythonをインストールすべき、そしてMicrosoft様はやくWindowsにバンドルしてくださいませ。
おわり。

