
これまで、PCカメラを利用したバーコードリーダーネタをいろいろやってきました。その中で、書籍のバーコード(ISBNコード)を読み取り、あらかじめ作成したリストの該当する書籍のセルにチェックを付けていくシステムを作りました。

デモ動画はこちら(音が出ます)。
在庫管理的な手法のサンプルとして作成したので、これはこれでいいのですが、実際に使うとしたら、これとは逆に蔵書のISBNコードを読み取ったら、その書籍の情報がExcelにどんどん入力されていくようにできればいろいろはかどりますね。
ISBNから書籍情報を取得したい
で、そのためにはISBNから書籍情報をひけるサービスが必要ですが、まぁあるんだろうなと調べてみると、やっぱりGoogleやらAmazonが提供していました。ここまでならさして驚きもしませんが、意外なことに我らが日本の国立国会図書館も書籍情報検索APIを公開しているではありませんか!
とは言え、今までの経験から「どうせ利用するのに本人確認書類と印鑑付きの申請書がいるんでしょ、ないな」と思っていたら、なんと個人利用非商用なら誰でも自由に使えてしまいます。
しかもGoogleやAmazonですら利用登録的な操作は必要なのですが、こちらは何の登録もいらずにただAPIをコールするだけで使えるので導入の手間が一番少ないです。リファレンスもしっかり用意されており、当然全部日本語でわかりやすく、ざっと読んでみたところ、要件を十分満たせそうなので、今回はこれを使って書籍情報を取得します。
正直、日本のお役所がここまで使えるシステムを運用しているとは思ってもみませんでした。他のお役所もぜひ見習ってください。
今回のシステムは前述のバーコード読み取りシステムをベースにして次のようになります。
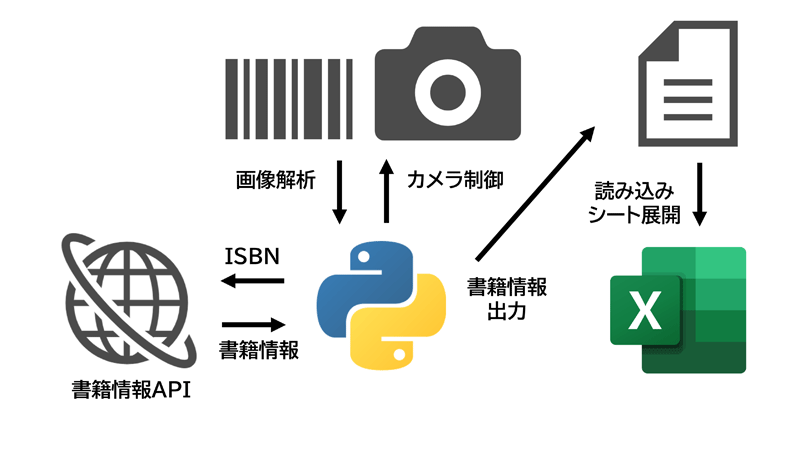
毎度おなじみExcelの存在意義が見当たらないですが、当サイトのコンセプト上、ここだけは譲れない。
国立国会図書館サーチAPIを使う
国立国会図書館が運用する国立国会図書館サーチAPIは一般的なREST APIでエンドポイントにパラメーター付きのHTTPリクエストを送信するとパラメーターに応じた処理をした結果が返ってきます。書籍のタイトル、著者、発行年などを検索条件として国立国会図書館をはじめ提携している全国の図書館が管理している書籍の情報を取得できます。
さて、APIを利用するためのプログラムですが、HTTPリクエストを組み立て送信するだけなのでVBAでもいけなくはないですが、概要図のとおりどっちみちバーコードリーダーをPythonでうごかすのと、この分野はPythonの方が圧倒的にコード量が少なくて済むのでPython側でやってしまいます。
まずはAPIまわりだけを関数化します。次のような関数を用意しました。
import requests
import xml.etree.ElementTree as et
def fetch_book_data(isbn):
endpoint = 'https://iss.ndl.go.jp/api/sru'
params = {'operation': 'searchRetrieve',
'query': f'isbn="{isbn}"',
'recordPacking': 'xml'}
res = requests.get(endpoint, params=params)
root = et.fromstring(res.text)
ns = {'dc': 'http://purl.org/dc/elements/1.1/'}
title = root.find('.//dc:title', ns).text
creator = root.find('.//dc:creator', ns).text
publisher = root.find('.//dc:publisher', ns).text
subject = root.find('.//dc:subject', ns).text
return isbn, title, creator, publisher, subject
国立国会図書館サーチAPIのエンドポイントはhttps://iss.ndl.go.jp/api/sruです。レスポンスはXMLです。
fetch_book_data関数はrequestsモジュールを使いエンドポイントにパラメーターを付けてHTTPリクエストを送信します。
requestsモジュールはほとんどの方が導入済みとは思いますが、標準モジュールではないので、まだの方はpipでインストールしましょう。
リクエストに含めるパラメーターはたくさん指定できますが、今回使うのは次の3つです。
| パラメーター | 値 | 意味 | 必須 |
|---|---|---|---|
| operation | searchRetrieve | APIの指定値 | ○ |
| query | 検索項目=検索値 | 検索条件の指定 | ○ |
| recordPacking | stringまたは xml | 書籍データの整形方式 |
operationはsearchRetrieveで固定です。
queryにはURLエンコードした検索クエリの文字列をセットします。requestsを使えば勝手にエンコードしてくれるので検索文字列そのままで大丈夫です。今回はISBNで検索するのでisbn=”{isbn}”で関数の引数として渡すISBNコードを埋め込みます。ISBN以外にも検索できる項目はいっぱいあるので、興味がある方はリファレンスを読んでみてください。
recordPackingはレスポンスのうち書籍情報の部分をURLエンコードした文字列にするか書籍情報以外のXMLにそのままXMLとして内包させるかを指定できます。省略した場合は前者です。XMLにしておいた方がデータを取り出すのが楽なのでxmlにしています。
レスポンスのXMLは次のようなものです。
<?xml version="1.0" encoding="UTF-8"?>
<searchRetrieveResponse xmlns="http://www.loc.gov/zing/srw/">
<version>1.2</version>
<numberOfRecords>2</numberOfRecords>
<nextRecordPosition>0</nextRecordPosition>
<extraResponseData>
~省略~
</extraResponseData>
<records>
<record>
<recordSchema>info:srw/schema/1/dc-v1.1</recordSchema>
<recordPacking>xml</recordPacking>
<recordData>
<srw_dc:dc xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:srw_dc="info:srw/schema/1/dc-v1.1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="info:srw/schema/1/dc-v1.1 http://www.loc.gov/standards/sru/dc-schema.xsd">
<dc:title>スッキリわかるPython入門</dc:title>
<dc:creator>国本大悟, 須藤秋良著</dc:creator>
<dc:subject>プログラミング(コンピュータ)</dc:subject>
<dc:description>監修: フレアリンク</dc:description>
<dc:description>"データ分析やAIの分野で注目されるプログラミング言語Pythonの入門書。プログラミングの基礎を丹念に解きほぐし、楽しいストーリーとともにしくみやコツをわかりやすく解説する。練習問題、エラー解決・虎の巻も収録。"--TRC MARCより</dc:description>
<dc:publisher>インプレス</dc:publisher>
<dc:language>jpn</dc:language>
</srw_dc:dc>
</recordData>
<recordPosition>1</recordPosition>
</record>
<record>
<recordSchema>info:srw/schema/1/dc-v1.1</recordSchema>
<recordPacking>xml</recordPacking>
<recordData>
<srw_dc:dc xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:srw_dc="info:srw/schema/1/dc-v1.1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="info:srw/schema/1/dc-v1.1 http://www.loc.gov/standards/sru/dc-schema.xsd">
<dc:title>スッキリわかるPython入門</dc:title>
<dc:creator>国本大悟, 須藤秋良 著,フレアリンク 監修</dc:creator>
<dc:subject>プログラミング (コンピュータ)</dc:subject>
<dc:description>索引あり</dc:description>
<dc:description>NDC(9版)はNDC(10版)を自動変換した値である。</dc:description>
<dc:publisher>インプレス</dc:publisher>
<dc:language>jpn</dc:language>
</srw_dc:dc>
</recordData>
<recordPosition>2</recordPosition>
</record>
</records>
</searchRetrieveResponse>
このXMLから必要な情報だけ取り出したいのでElementTreeを使います。ハマりポイントは書籍情報タグには名前空間が設定されているので、名前空間のPrefixと値の関係をディクショナリにしてfindメソッドの第二引数に渡さないとうまくヒットしません。
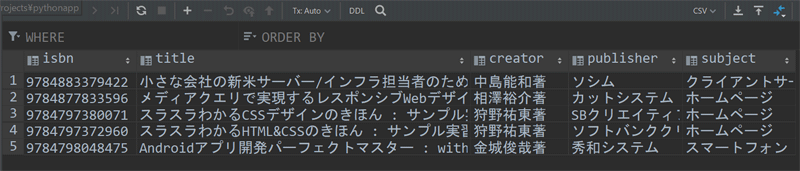
検索に使用したISBNと、書籍情報からタイトル、著者、出版社、分類をタプルでまとめて関数の戻り値にしています。
ためしに次のコードを実行してみます。
print(fetch_book_data('9784295006329'))実行結果は

必要な情報だけを取り出せました。
バーコードリーダーと連携する
バーコードリーダープログラムは最初に紹介した記事のものを基本流用します。カメラを起動し、バーコードを読み取り、結果をテキストファイルへ書き出します。
追加機能としてfetch_book_data関数と、APIを無駄にコールしないようにコード検証の関数を実装します。
次のようになりました。
import requests
import xml.etree.ElementTree as et
import winsound
import csv
import cv2
from pyzbar.pyzbar import decode
BUF_FILE_PATH = r'd:\bookshelf\buf.csv'
def cam_capture():
cap = cv2.VideoCapture(1)
font = cv2.FONT_HERSHEY_SIMPLEX
barcodes = []
while cap.isOpened():
ret, frame = cap.read()
if ret:
d = decode(frame)
if d:
for barcode in d:
barcode_data = barcode.data.decode('utf-8')
if is_isbn(barcode_data):
if barcode_data not in barcodes:
barcodes.append(barcode_data)
winsound.Beep(2000, 50)
font_color = (0, 0, 255)
result = fetch_book_data(barcode_data)
with open(BUF_FILE_PATH,
mode='a',
encoding='shift-jis',
newline='') as buf:
writer = csv.writer(buf)
writer.writerow(list(result))
else:
font_color = (0, 154, 87)
x, y, w, h = barcode.rect
cv2.rectangle(frame, (x, y), (x + w, y + h), font_color, 2)
frame = cv2.putText(frame, barcode_data, (x, y - 10),
font, .5, font_color, 2, cv2.LINE_AA)
cv2.imshow('BARCODE READER Press Q -> Exit', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
def fetch_book_data(isbn):
endpoint = 'https://iss.ndl.go.jp/api/sru'
params = {'operation': 'searchRetrieve',
'query': f'isbn="{isbn}"',
'recordPacking': 'xml'}
res = requests.get(endpoint, params=params)
root = et.fromstring(res.text)
ns = {'dc': 'http://purl.org/dc/elements/1.1/'}
title = root.find('.//dc:title', ns).text
creator = root.find('.//dc:creator', ns).text
publisher = root.find('.//dc:publisher', ns).text
subject = root.find('.//dc:subject', ns).text
return isbn, title, creator, publisher, subject
def is_isbn(code):
return len(code) == 13 and code[:3] == '978'
バーコードリーダーとしての詳細は別記事を参照していただくとして、このプログラムの動作にはopencv-pythonとpyzbarが必要です。
うごきとしてはカメラで写した映像からバーコードを解析し、はじめて読み取ったISBNコードであるなら、barcodesリスト(読み取り値キャッシュ)へ追加してからビープ音をならしバーコードを赤枠でトラッキングします。そして読み取り値をHTTPリクエストのパラメーターに組み込んでAPIをコールします。レスポンスのXMLから必要な値だけのタプルを作り、それをCSVとして書き出します。
すでに読み取っているISBNコードであれば音はならず、緑枠でトラッキングします。
ISBNではないバーコードは音も枠も出ません。
is_isbn関数は引数がISBNかどうかを判定します。引数が13桁であり、978で始まっているならTrueを返します。もっと厳密にやるならチェックサムを計算して評価するのがいいのでしょうが、そこまでの正確さは求めないので簡単に。
その他、ちゃんとやるならレスポンスのステータスが200以外だった場合のエラーハンドラーが必要ですが、省略。
Excelと連携する
もはやExcelである必要は全くないのですが、Pythonが書き出したCSVをテーブルへ取り込み自動更新プロシージャで表示させます。手法は最初に紹介した記事と同じです。一応コードを載せておきます。
Public tm As Date
Sub executePy()
Dim wss As Object
Set wss = CreateObject("WScript.Shell")
Dim cmd As String
cmd = "python D:\bookshelf\isbn_cam.py"
wss.Run cmd, 0, False
End Sub
Sub startTableRefresh()
Worksheets("buf").Range("a1").ListObject.QueryTable.Refresh
tm = Now + TimeValue("00:00:05")
Application.OnTime tm, "startTableRefresh"
End Sub
Sub stopTableRefresh()
On Error Resume Next
Application.OnTime tm, "startTableRefresh", Schedule:=False
End Sub
Sub main()
Call executePy
Call startTableRefresh
End Sub
Excelの外部データ取り込み機能で、Pythonが書き出したCSVをシートへ取り込んでいます。これを5秒毎に更新しています。
STARTボタンにmainプロシージャを割り当て実行します。
デモ動画はこちら(音がでます)。
APIコールが入るので若干もっさり感がありますが、許容範囲内とします。どうせ5秒更新なので。読み取り後を別スレッドでやらせるといいかもしれません。
全部Pythonでやる
はじめからそうしとけという突っ込みは聞こえません。これまた別記事でやったネタを再利用します。

コードはISBN用に多少手直しをして次のようにしました。詳細は↑の記事をご覧ください。
import json
import sqlite3
import cv2
import requests
import winsound
import threading
import xml.etree.ElementTree as et
from pyzbar.pyzbar import decode
from http.server import BaseHTTPRequestHandler, ThreadingHTTPServer
from websocket_server import WebsocketServer
class OrenoServer:
def __init__(self):
self.HOST = 'localhost'
self.HTTP_PORT = 8080
self.WS_PORT = 8081
self.client = None
self.wss = WebsocketServer(host=self.HOST, port=self.WS_PORT)
self.wss.set_fn_new_client(self.new_client)
self.https = ThreadingHTTPServer((self.HOST, self.HTTP_PORT), HttpHandler)
def start(self):
threading.Thread(target=self.wss.run_forever).start()
threading.Thread(target=self.https.serve_forever).start()
def shutdown(self):
self.wss.shutdown()
self.https.shutdown()
def new_client(self, client, server):
if self.client is None:
self.client = client
threading.Thread(target=self.cam_capture).start()
def cam_capture(self):
cap = cv2.VideoCapture(1)
font = cv2.FONT_HERSHEY_SIMPLEX
barcodes = []
db = OrenoDataBase()
while cap.isOpened():
ret, frame = cap.read()
if ret:
d = decode(frame)
if d:
for barcode in d:
barcode_data = barcode.data.decode('utf-8')
if self.is_isbn(barcode_data):
if barcode_data not in barcodes:
barcodes.append(barcode_data)
winsound.Beep(2000, 50)
font_color = (0, 0, 255)
result = self.fetch_book_data(barcode_data)
self.wss.send_message(self.client, json.dumps(result))
db.set(result)
else:
font_color = (0, 154, 87)
x, y, w, h = barcode.rect
cv2.rectangle(frame, (x, y), (x + w, y + h), font_color, 2)
frame = cv2.putText(frame, barcode_data, (x, y - 10),
font, .5, font_color, 2, cv2.LINE_AA)
cv2.imshow('BARCODE READER Press Q -> Exit', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
db.close()
cap.release()
self.shutdown()
def fetch_book_data(self, isbn):
endpoint = 'https://iss.ndl.go.jp/api/sru'
params = {'operation': 'searchRetrieve',
'query': f'isbn="{isbn}"',
'recordPacking': 'xml'}
res = requests.get(endpoint, params=params)
root = et.fromstring(res.text)
ns = {'dc': 'http://purl.org/dc/elements/1.1/'}
title = root.find('.//dc:title', ns).text
creator = root.find('.//dc:creator', ns).text
publisher = root.find('.//dc:publisher', ns).text
subject = root.find('.//dc:subject', ns).text
return isbn, title, creator, publisher, subject
def is_isbn(self, code):
return len(code) == 13 and code[:3] == '978'
class OrenoDataBase:
def __init__(self):
self.conn = sqlite3.connect(r'D:\bookshelf\isbn_ndl.sqlite')
self.conn.row_factory = sqlite3.Row
self.cur = self.conn.cursor()
def get(self):
self.cur.execute('SELECT * FROM ndl')
rows = []
for r in self.cur.fetchall():
rows.append({'isbn': r['isbn'], 'title': r['title'], 'creator': r['creator'],
'publisher': r['publisher'], 'subject': r['subject']})
return rows
def set(self, values):
place_holder = ','.join('?'*len(values))
self.cur.execute(f'INSERT INTO ndl VALUES ({place_holder})', values)
self.conn.commit()
def close(self):
self.cur.close()
self.conn.close()
class HttpHandler(BaseHTTPRequestHandler):
def do_GET(self):
with open(r'D:\bookshelf\template.html', mode='r', encoding='utf-8') as html:
response_body = html.read()
self.send_response(200)
self.send_header('Content-type', 'text/html; charset=utf-8')
self.end_headers()
self.wfile.write(response_body.encode('utf-8'))
def do_POST(self):
db = OrenoDataBase()
rows = db.get()
self.send_response(200)
self.send_header('Content-type', 'application/json')
self.end_headers()
response_body = json.dumps(rows)
self.wfile.write(response_body.encode('utf-8'))
db.close()
server = OrenoServer()
server.start()表示用のHTML(template.html)は次のようにしました。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
Bootstrap読み込み省略
<script>
const HTTP_PORT = 8080
const WS_PORT = 8081
let wss = new WebSocket('ws://localhost:' + WS_PORT)
wss.onmessage = function (e) {
let data = JSON.parse(e.data)
let row = '<tr>'
row += '<td>' + data[0] + '</td>'
row += '<td>' + data[1] + '</td>'
row += '<td>' + data[2] + '</td>'
row += '<td>' + data[3] + '</td>'
row += '<td>' + data[4] + '</td>'
row += '</tr>'
$('#tb').append(row)
}
$.ajax({
url: 'http://localhost:' + HTTP_PORT,
type: 'POST',
dataType: 'json',
}).then(
function (data) {
let elem = '<tr><th>ISBN</th><th>タイトル</th><th>著者</th>' +
'<th>出版社</th><th>分類</th></tr>'
$.each(data, function (key, item) {
elem += '<tr>'
elem += '<td>' + item.isbn + '</td>'
elem += '<td>' + item.title + '</td>'
elem += '<td>' + item.creator + '</td>'
elem += '<td>' + item.publisher + '</td>'
elem += '<td>' + item.subject + '</td>'
elem += '<tr>'
})
$('#tb').html(elem)
})
</script>
<title>蔵書リスト</title>
</head>
<body>
<div class="container">
<table class="table table-striped table-dark" id="tb">
</table>
</div>
</body>
</html>
スクリプトを起動してlocalhost:8080へアクセスするとカメラが起動するので、ISBNを読み取っていくとAPIで取得した情報がテーブルに追加されていきます。
デモ動画はこちら(音が出ます)。
やっぱりAPIコールで画像がカクつくので、別スレッドでやるのがいいですね。やりませんけど。用途的に1回つかったらもう出番はないのでこれでいいかなと。
データはSQLiteに保存されていますので、あとはExcelにするなり如何様にもなりますね。
まとめ
国立国会図書館サーチAPIはデータの品質はイマイチですが(例えば著者が「えくせる太郎著」だったり「えくせる太郎」だったり、出版社の(株)がなかったり、同じ会社で略称だったり、そうでなかったり)個人利用であれば必要十分ではないでしょうか。なんと言っても何の登録もなしにいきなり使えるのが最大の利点です。
なお普通は公開されているAPIコール数の上限ですが、非公開です。アカウントごとにカウントできるわけでもないという理由もあるかと思いますが「あんまり連続でやるなよ」としか書かれておりません。デモ動画を見てもらえばわかりますが、1冊ずつ読ませていく分には大丈夫そうです。秒間100回みたいな無茶なリクエストをしなければ問題ないのではないでしょうか。
私の手持ちの本のはありませんでしたが、書影(本の画像)が用意されていれば、それをダウンロードできるAPIもあります。
日本国民として遠慮なく使わせてもらいましょう。
おわり。

